
Multiple AI models help robots execute complex plans more transparently
A multimodal system uses models trained on language, vision, and action data to help robots develop and execute plans for household, construction, and manufacturing tasks.
A multimodal system uses models trained on language, vision, and action data to help robots develop and execute plans for household, construction, and manufacturing tasks.

This new method draws on 200-year-old geometric foundations to give artists control over the appearance of animated characters.

“Minimum viewing time” benchmark gauges image recognition complexity for AI systems by measuring the time needed for accurate human identification.

Justin Solomon applies modern geometric techniques to solve problems in computer vision, machine learning, statistics, and beyond.

MIT CSAIL researchers innovate with synthetic imagery to train AI, paving the way for more efficient and bias-reduced machine learning.

Computer vision enables contact-free 3D printing, letting engineers print with high-performance materials they couldn’t use before.

By blending 2D images with foundation models to build 3D feature fields, a new MIT method helps robots understand and manipulate nearby objects with open-ended language prompts.
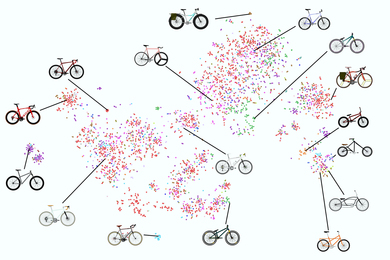
AI models that prioritize similarity falter when asked to design something completely new.

Amid the race to make AI bigger and better, Lincoln Laboratory is developing ways to reduce power, train efficiently, and make energy use transparent.

Inspired by physics, a new generative model PFGM++ outperforms diffusion models in image generation.

Researchers use multiple AI models to collaborate, debate, and improve their reasoning abilities to advance the performance of LLMs while increasing accountability and factual accuracy.

The machine-learning method works on most mobile devices and could be expanded to assess other motor disorders outside of the doctor’s office.

Researchers use synthetic data to improve a model’s ability to grasp conceptual information, which could enhance automatic captioning and question-answering systems.

The system could improve image quality in video streaming or help autonomous vehicles identify road hazards in real-time.

The challenge involves more than just a blurry JPEG. Fixing motion artifacts in medical imaging requires a more sophisticated approach.